

A cool project you never heard of
Back in the day, there were two distinct paths for making computers "think." The first was a family of inventions that includes multi-layer perceptrons, neural nets, genetic programming and machine learning--and now LLMs. These are forms of curve-fitting. Just a few years ago, higher order curve-fitting appeared as the science behind deciding what kind of music you'd like to hear next, or what else you might want to buy. It's gotten a lot more sophisticated, and is now called "AI."
The other old-school approach to making computers "think" is the product of linguistics and epistemology. In the 1970s, classical Natural Language Processing (NLP) was a popular pursuit, and it seemed like an academic avenue that would bear intelligent computing more quickly than curve-fitting. But, NLP was difficult, brittle and not scalable. Excitement waned and lesser forms of artificial intelligence, such a Expert Systems, took the limelight until their prospects dimmed as well. NLP has since come to mean other disciplines like text summarization, translation, data mining and command-and-control, like Siri.
Brainhat is not AI in the current sense
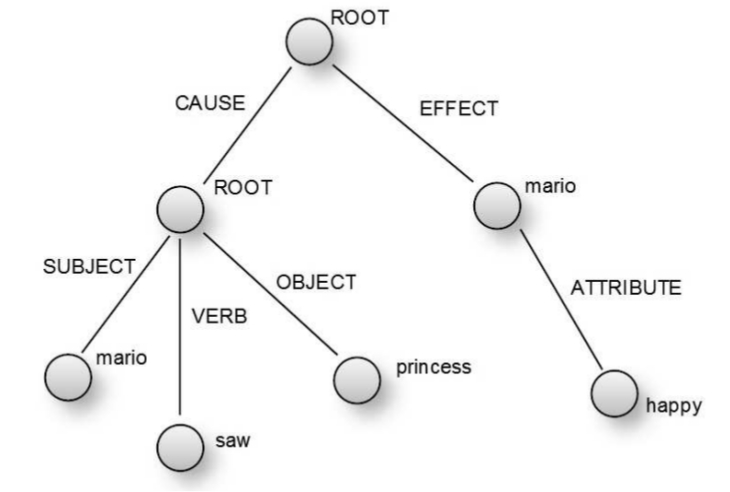
| Brainhat is a lonely adult orphan of this second approach to teaching computers to "think," thirty years in the making. It treats human language like a programming language with executable statements and branches. The problems of brittleness and scale are addressed with coarse-grained parallelism. A Brainhat instance can include an unlimited number of computers, each with their own knowledge domains. And, that same swarm of machines can serve many users, all at once. Where toy implementations with old-school NLP systems fail, Brainhat approaches the problem with Gestalt. |
|